




When ChatGPT Plus first launched in early 2023, users had no straightforward way to prevent their conversations from being used to train OpenAI’s models. By default, anything you typed into ChatGPT could become fodder for model improvement. The only partial workaround introduced later was to turn off chat history entirely – a feature added in April 2023 that stopped those specific conversations from being used in training (though it also meant you lost the convenience of having past chats saved). In other words, paying for ChatGPT Plus didn’t initially grant any extra privacy; your data was still helping to “make ChatGPT better for everyone,” unless you opted to hide your chat history.
Fast forward a few months, and OpenAI rolled out ChatGPT Team and ChatGPT Enterprise plans aimed at businesses. A notable change in these offerings was a promise of data privacy: by default, OpenAI would not use business customers’ prompts or conversations to train its models. Enterprise users could chat with confidence that their company secrets weren’t secretly contributing to the next GPT model. API users were given similar assurances around that time – data submitted via the API would not be used for training unless an organization explicitly opted in. These changes acknowledged a reality: many users (especially companies) demanded the ability to opt out of model training.
Eventually, OpenAI extended a form of opt-out to everyone, including Free and Plus users. However, in classic fashion, the option wasn’t emblazoned on a big red button labeled “Do NOT train on my data.” Instead, it was tucked away behind vague settings and multiple layers of menus. Disabling training on your ChatGPT data has become an Easter egg hunt of sorts – a journey through benign-sounding settings and subtle links. In this post, we’ll walk through how to navigate that process step by step. Along the way, we’ll note the odd UI decisions that make disabling data training a bit more convoluted (with just a touch of irony at their expense).
Video tutorial
Here is a short video tutorial that explains step by step how to prevent ChatGPT from training with your content.
Locating the “Improve the model for everyone” Setting
The first place to stop ChatGPT from learning from your conversations is the ChatGPT app’s own settings. In the ChatGPT interface (Free or Plus), click on your account profile menu (the bottom-left corner of the sidebar) and choose Settings – this opens the configuration dialog for ChatGPT (see screenshot 01).
Screenshot 01: Opening the Settings menu in ChatGPT’s interface (web version).
Within the Settings dialog, navigate to Data Controls. Here you’ll find a toggle labeled “Improve the model for everyone.” By default, this is switched on for standard users, meaning your chat content may be used to improve future models. Screenshot 02 shows how this Data Controls section looks – you can see Improve the model for everyone among other options like data export and chat history controls.
Screenshot 02: The Data Controls panel in ChatGPT settings, with the Improve the model for everyone option visible (in this case, turned on).
So what exactly does this toggle do? Essentially, it lets you decide whether your conversations can be used to train and improve ChatGPT’s models. If you turn it off, OpenAI says your new conversations will not be used in training runs. Notably, your chat history will still be saved and accessible to you – turning off model training no longer wipes out your history the way the old “Chat History & Training” toggle did in 2023. As the OpenAI help center notes, “Your conversations will still appear in your chat history but won’t be used to train ChatGPT”. In other words, you can keep the handy sidebar history while saying “no thanks” to contributing to the AI’s education.
It’s worth pointing out the phrasing here. “Improve the model for everyone” is a curiously feel-good way to describe our data being used for training. By labeling the opt-out as turning off something that would “help everyone,” the UI subtly nudges users to leave it on. (After all, who wants to deny improving the model for all mankind?) This little design choice might induce a wry smile – you have to disable an altruism-sounding feature to protect your own data. 🧐
Now, if you click on the Improve the model for everyone setting in the Data Controls menu, you’ll see more details about what it means. Screenshot 03 shows the description provided: it explains that allowing this will let your content be used to train OpenAI’s models to make ChatGPT better, and it assures that “we take steps to protect your privacy.” More importantly, on this screen you’ll find an unassuming link for additional information (labeled as “Learn more”).
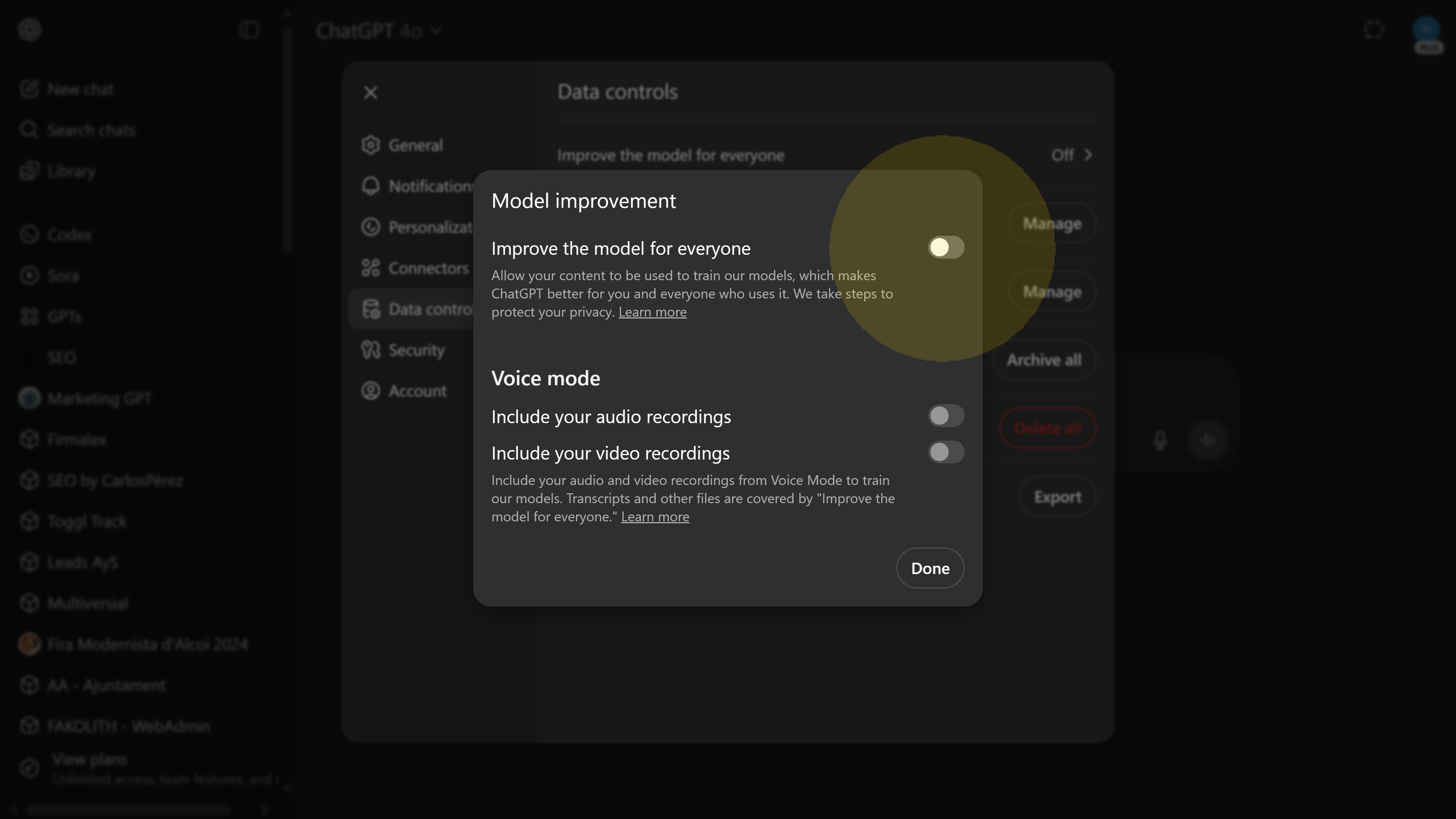
Screenshot 03: The ChatGPT Data Controls detail view for model training.
Go ahead and toggle off “Improve the model for everyone.” Once you switch this off, any new conversations should not be used to improve the AI model. However – and this is important – this toggle does not fully guarantee your data won’t be used in any model training. Turning it off will stop most training usage of your future chats, but there are a few caveats:
- Past conversations: The opt-out isn’t retroactive. Any data you’ve already contributed in the past may still reside in training datasets (especially if it was already disassociated from your account). OpenAI’s disclaimer makes it clear that this request “applies moving forward and does not apply to data that was previously disassociated from my account” (as seen on the upcoming form). In plain terms, turning it off now won’t un-train the model on what you said yesterday. It only affects new conversations.
- Data retention: Even with training off, OpenAI will still retain your conversations on their servers for a period of time. Previously, when history was disabled, they stated they retain new chats for 30 days to monitor for abuse before deleting. With the current setup, if your history is on but training off, your chats remain visible to you and likely stored by OpenAI indefinitely (or as long as needed), just not used for model improvement.
- Explicit feedback: Opting out via this toggle doesn’t prevent all forms of your data from influencing the model. For example, if you provide a thumbs-up or thumbs-down rating on a response, you are explicitly sending feedback to OpenAI. According to OpenAI, if you choose to give feedback on a ChatGPT answer, “the entire conversation associated with that feedback may be used to train our models,” even if you’ve otherwise opted out. So, giving a 👍 on an answer is effectively opting that specific exchange into training. Keep that in mind before you click those feedback buttons.
In summary, switching off Improve the model for everyone is a big step toward privacy, but it isn’t a complete “no training ever” guarantee. For truly belt-and-suspenders protection, OpenAI has introduced a more formal opt-out process – one that is, bafflingly, even more hidden in the interface. Let’s explore that next.
Fully Disabling Training via OpenAI’s Privacy Portal
After turning off the ChatGPT toggle, you might reasonably assume you’re done. But OpenAI has a second layer of opt-out, accessible through its privacy platform. Finding it is half the challenge. Remember that “Learn more” link mentioned earlier (screenshot 03) This is your gateway to the full opt-out, though it’s hardly obvious. Clicking that link doesn’t directly give you a checkbox to opt out; instead, it whisks you to an OpenAI Help Center article about “How your data is used to improve model performance.” There, buried in the text, is the real prize: a link to OpenAI’s Privacy Portal where you can submit an official request not to train on your content.
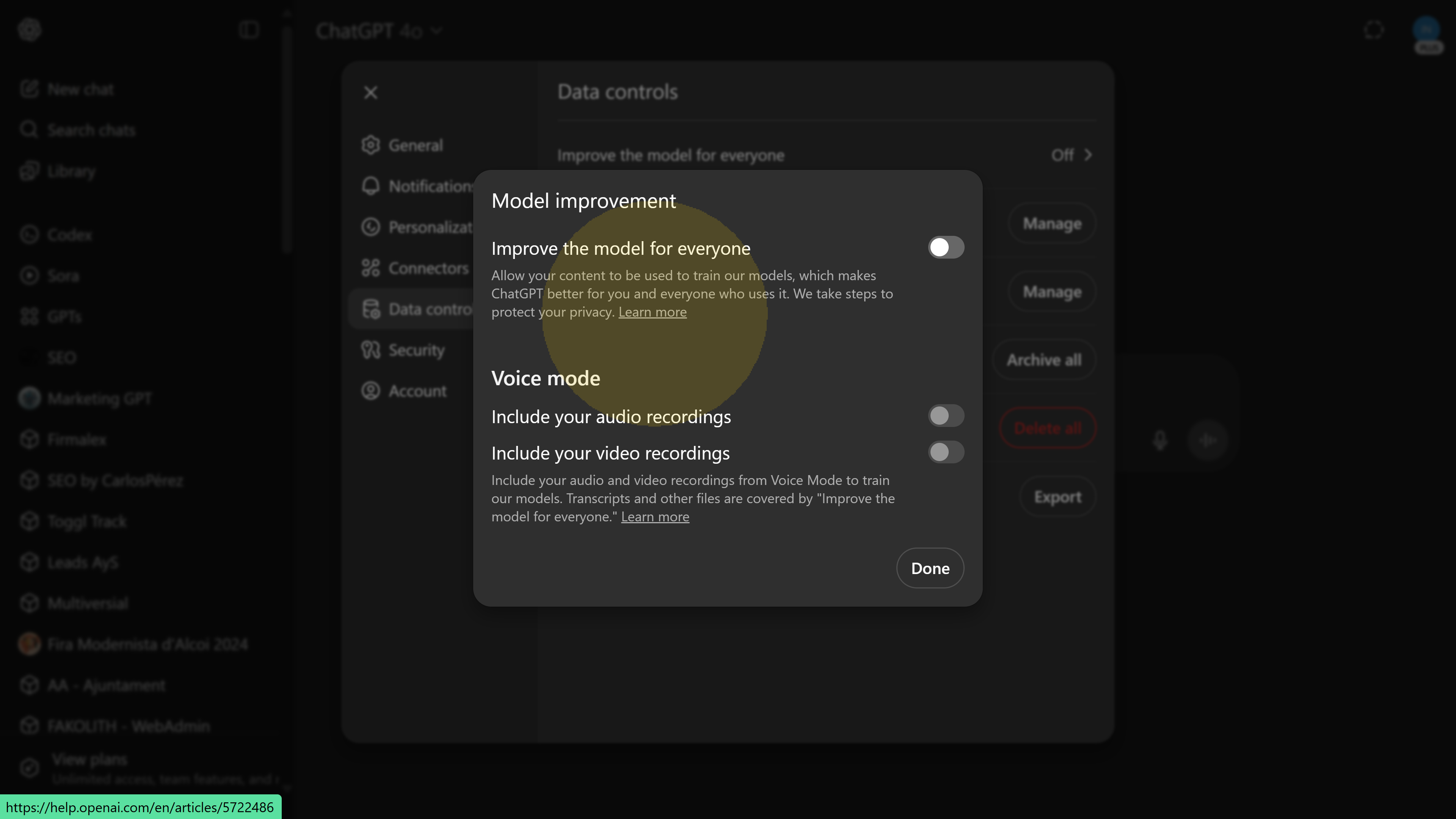
Screenshot 04: Note the description of what allowing training entails, and the small “Learn more” link for further steps.
For example, screenshot 05 shows a snippet of the Help Center article that opens from the “Learn more” link. It explains that for services like ChatGPT, “you can opt out of training through our privacy portal by clicking on ‘Do not train on my content.’”. In other words, OpenAI didn’t put the full opt-out in the ChatGPT app’s UI; they put it on a separate web portal that you learn about via a support article. 🤦♂️
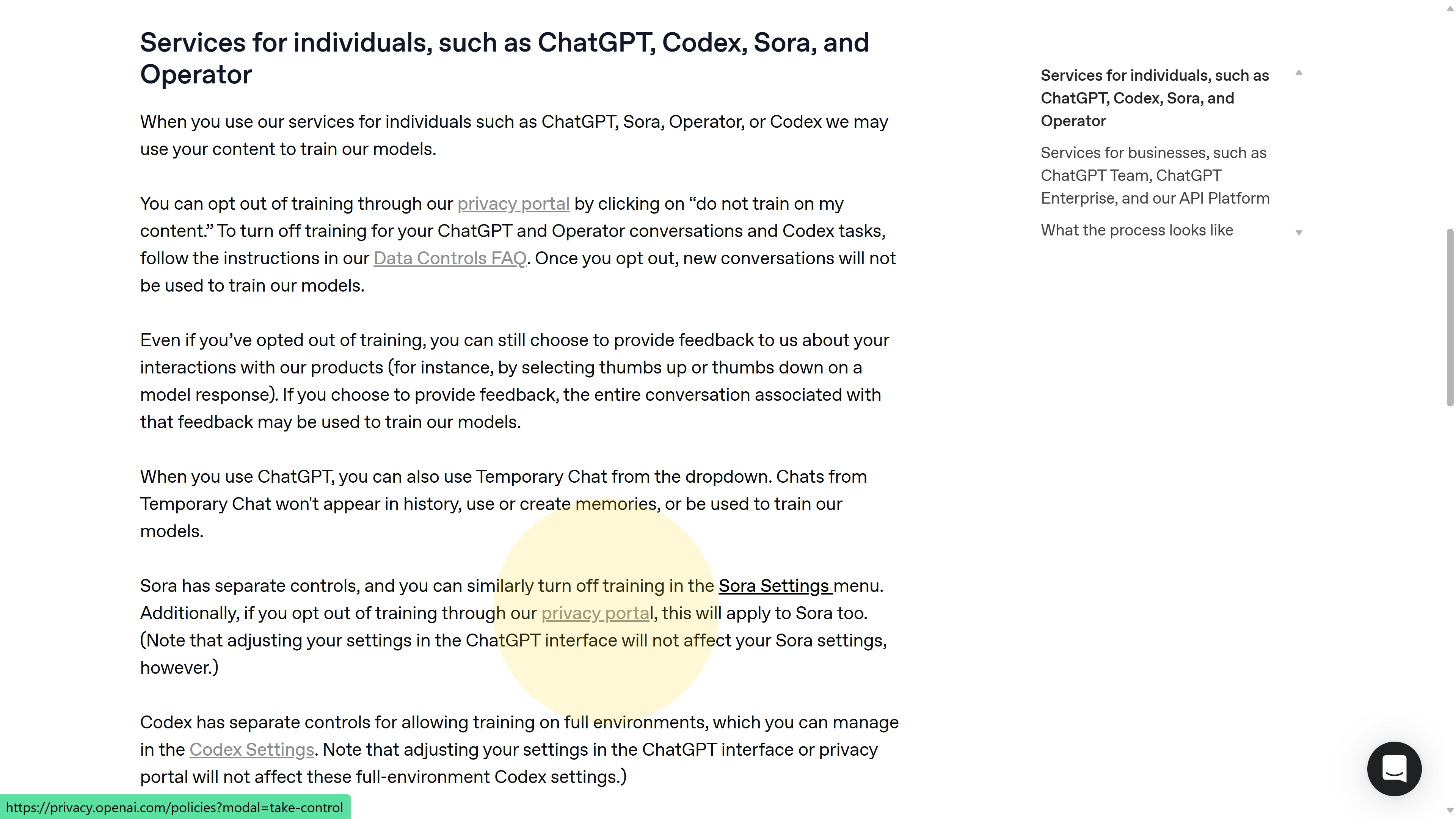
Screenshot 05: Excerpt from OpenAI’s Help Center article. It outlines that ChatGPT (and other consumer services) may use your content for training unless you opt out via the privacy portal’s “Do not train on my content” option.
So, how do we actually complete this “Do not train on my content” request? Here’s a step-by-step guide:
1.- Open the OpenAI Privacy Portal. You can reach this portal either by following the link in the help article (described above) or by navigating directly to OpenAI’s privacy center (you’ll need to log in with your OpenAI account). Once there, you’ll see a dashboard of privacy options. Look for the option that says “Do not train on my content.” In the screenshot below (screenshot 06), you can see the privacy portal’s main menu – the Do not train on my content request is one of the choices available (alongside data download and account deletion tools).
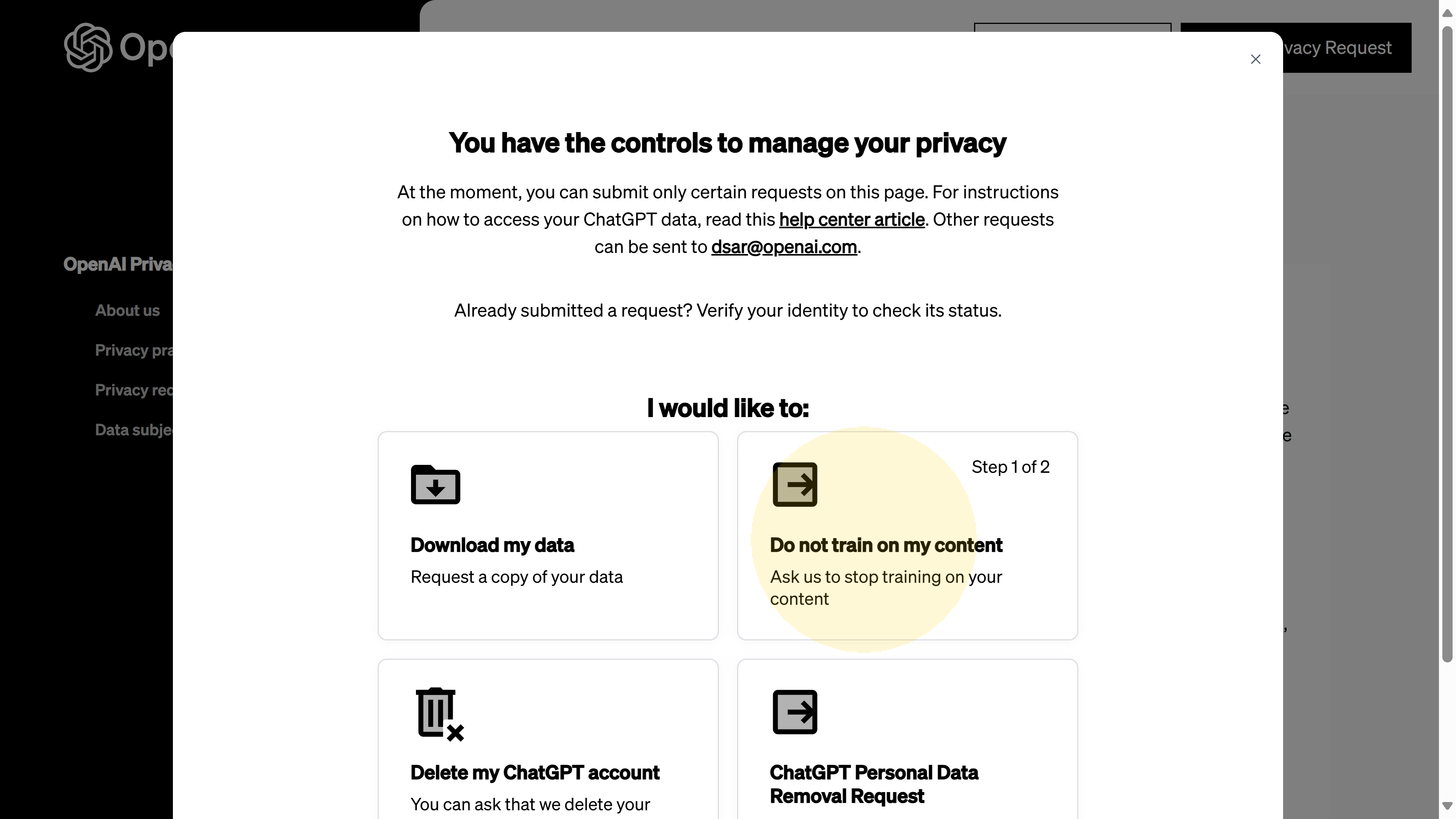
Screenshot 06: The OpenAI Privacy Portal main page. Users can choose among actions like downloading data, opting out of training, or deleting accounts. Here, “Do not train on my content” is the option we need to select.
2.-Initiate the opt-out request. Click “Do not train on my content.” The portal will present a brief explanation and a confirmation form. This step is not just a single click – OpenAI wants to make sure you understand what you’re asking for. You’ll see some text explaining that one of the key benefits of AI models is learning from user data, etc., and that by opting out, your future content won’t be used to improve the models. Crucially, it notes (in fine print) that this will only apply going forward, not retroactively to data that’s already been processed. To proceed, you must check a box acknowledging you understand these terms.
3.-Provide your region and submit. After ticking the confirmation box, you’ll need to select your country/state of residence from a dropdown menu. This likely has to do with region-specific privacy regulations. Choose the appropriate region that matches your account’s jurisdiction. In screenshot 07, you can see the form once the checkbox is ticked and the region (e.g., Spain) is selected – at this point the “Submit Request” button becomes enabled.
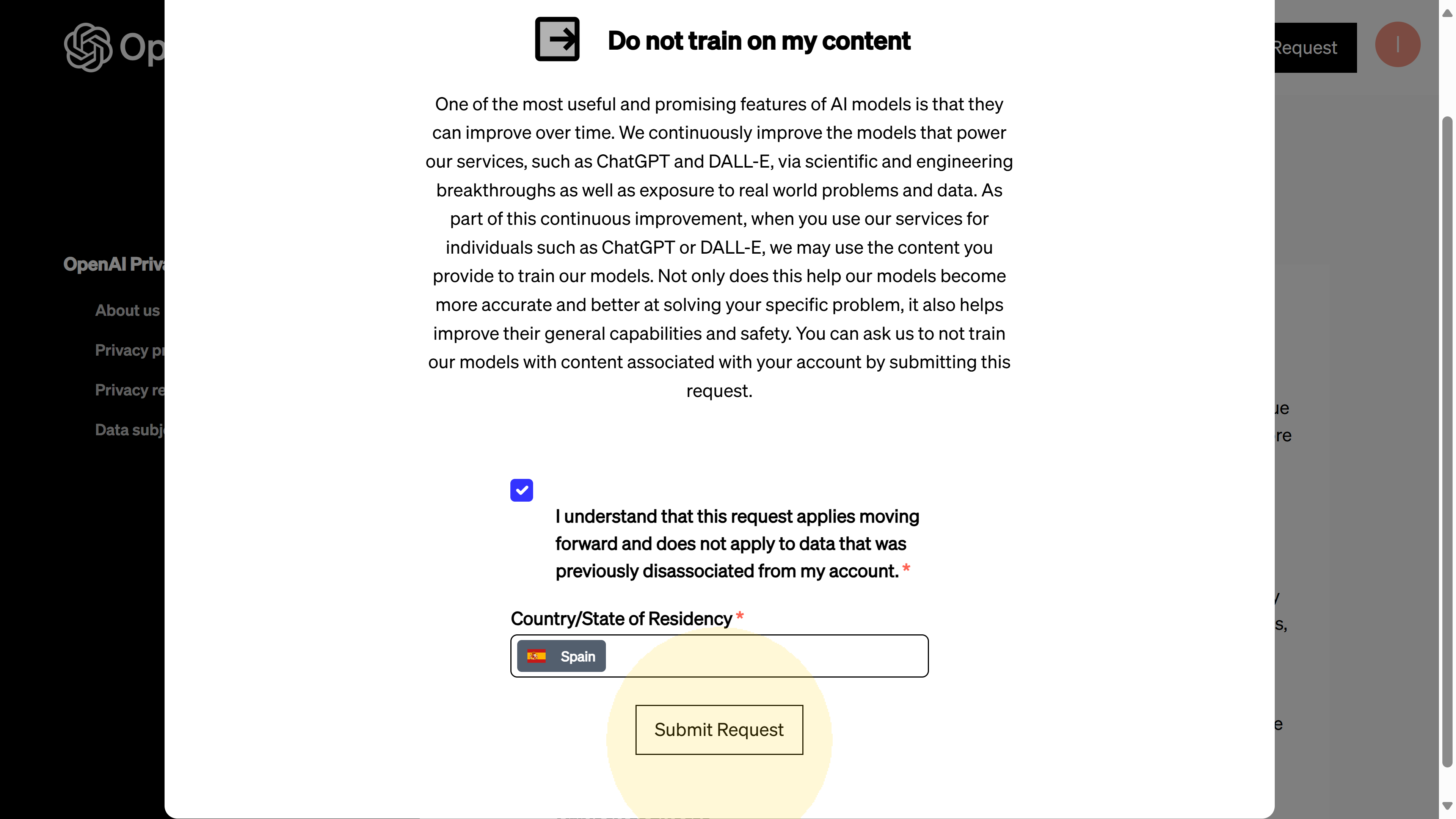
Screenshot 07: Completing the opt-out form by selecting the region of residence (after checking the box). The form is now ready, and the Submit request button is active.
Now click Submit request. The portal will process your opt-out submission. You should see an on-screen confirmation that your request was received.
4.- Confirmation of opt-out. Once submitted, the Privacy Portal will show a success message indicating your request has been registered. Screenshot 08 shows the confirmation you get immediately after hitting submit – a friendly green check mark and a note that your “Do not train” request was submitted successfully.
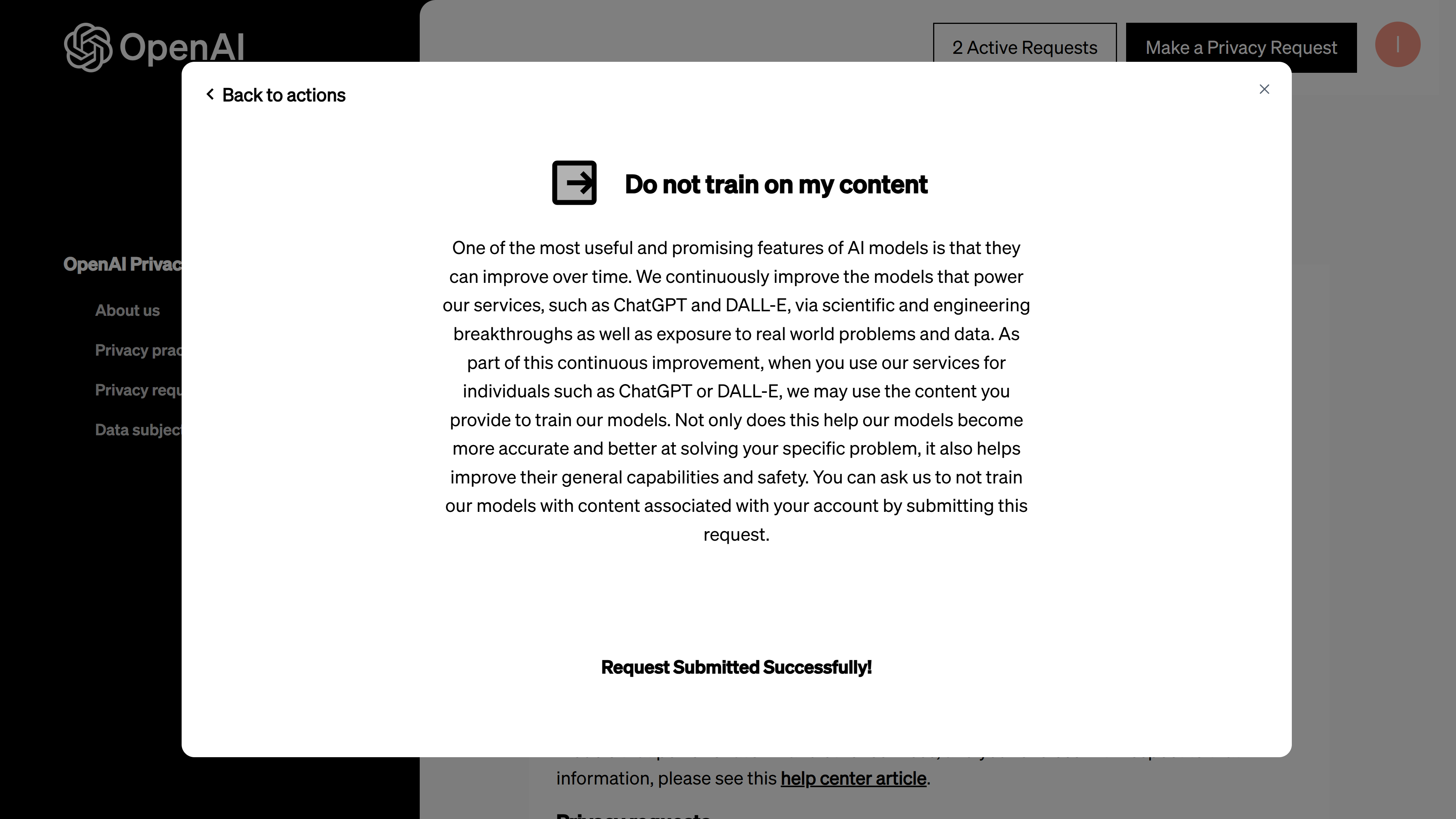
Screenshot 08: Confirmation message after submitting the Do not train on my content request. The request has been successfully logged in OpenAI’s system.
5.- Track request status (and be patient). After submission, your opt-out request appears in the Privacy Portal’s Requests list. OpenAI will also send you an email confirming that they received the request for your records. The actual “Do not train” flag on your account is likely applied immediately or very quickly, but the formal request might take some time to fully process or complete on their end. In screenshot 09, you can see the Requests status page showing an active Do not train on my content request (along with another request I had made earlier). It shows the date and that it’s in progress. You don’t need to do anything else at this point – just know that it’s on file. Once the request is processed, you should get a confirmation email and the status may update to completed.
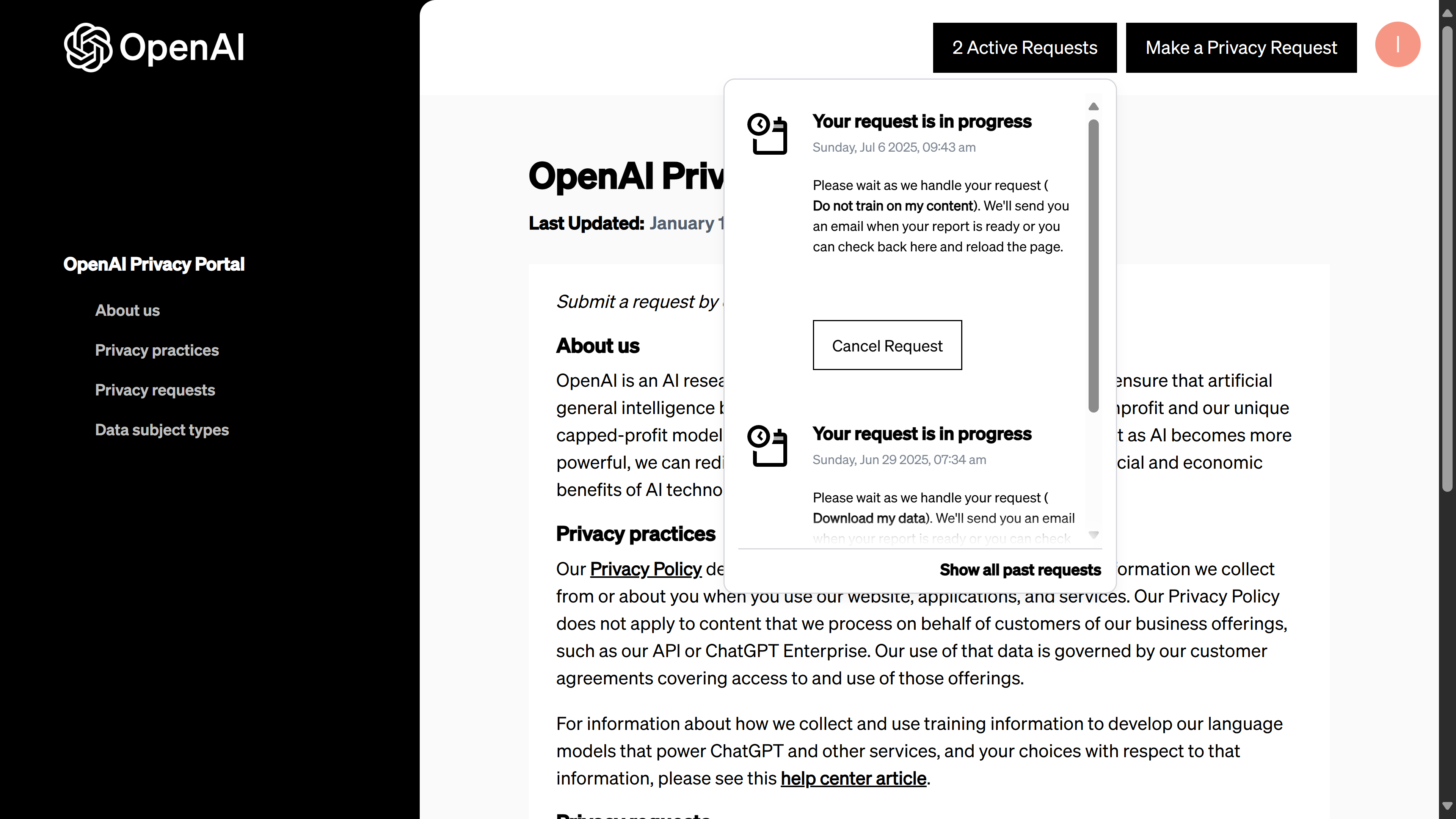
Screenshot 09: The OpenAI Privacy Portal’s request status page. Here my Do not train on my content request (from Jul 6, 2025) is listed as “in progress.” For context, a prior Download my data request (from June 29, 2025) is also shown – it took nearly a week to complete.
Note: The Privacy Portal is also where you can export your data. As shown above, I had requested a data export before opting out of training. In my case, that data download took 6 days to be prepared, and when it finally arrived, it was… comprehensive, to say the least. It included pretty much everything: conversations, uploaded images and files, voice recordings, invoices, payments, contacts, and more (some GBs in my case 😅). Honestly, I don’t even want to think about what a hacker — or OpenAI itself — could do with all that. If you’re curious about what they’ve stored on you, the export option is definitely worth a look. Just be prepared: it’s not a quick process.
By following the steps above, you’ve effectively told OpenAI “please don’t use my content to train your models.” This two-layer approach – toggling off in the app and then formally opting out via the portal – should cover your bases. It’s admittedly more convoluted than one would hope. The fact that the full opt-out lives behind a tiny “Learn more” link within a settings submenu is, to put it mildly, an interesting UX choice. One might suspect that OpenAI isn’t eager for every user to easily find and flip this switch. But for those of us concerned about data privacy, the option does exist, and now you know how to find it.
A Note on Pro, Enterprise, Team, and API Users
If you’re using ChatGPT in a professional or organizational context (or using the OpenAI API), you may not need to jump through these hoops at all. ChatGPT Pro, ChatGPT Team, ChatGPT Enterprise, and API users have data training disabled by default – OpenAI does not use inputs or outputs from these services to train models. This is part of the enterprise-grade privacy commitments they’ve made. So, if you’re on one of those plans, your content isn’t being fed into model updates (unless you explicitly opt in or give feedback). You already have what the rest of us are trying to achieve: peace of mind that your data stays private.
In summary, disabling training on your data in ChatGPT is possible, but not exactly obvious. Free and Plus users should turn off “Improve the model for everyone” in their settings, and then go the extra mile by submitting a opt-out request via OpenAI’s privacy portal. It’s a few minutes of effort that ensures your future conversations remain yours and not a part of the AI’s training diet. While OpenAI’s interface might make this feel like finding a secret setting, at least now you have the map. Happy chatting – on your terms!




Leave a Reply